Learn How the Google Search Engine searches the interNet.
Larry Page 2400 E. Bayshore Parkway Mountain View, CA 94043
[p]1.650.318.0200
Sergey Brin, Escondido Village #22D Stanford, CA 94305
1.415.497.0753 Fax +1.415.725.7411 or +1.415.725.2588 (2002)


The Google motto is "do no evil"
By their fruits you shall know them --
evil is as evil does
."
Once their arrogance was intimidating and awesome. Now google just seems clueless. Systematic degradation, they seem to be rotting from the inside out. "The bleak reality of corporate growth" is that "efficiencies of scale are almost always outweighed by the burdens of bureaucracy."
"We are moving to a Google that knows more about you." — Google CEO Eric Schmidt
Google CEO Eric Schmidt says the company's " policy is to get right up to the creepy line and not cross it. " The problem with Google is that Eric Schmidt is creepy. "People who don't like Google's Street View cars taking pictures of their homes and businesses "can just move" ".
Google Algorythm vs rank really done by Humans
Google human raters.
Remember: “The Adventures of Tom Sawyer” where Tom cajoles his
guileless friends into whitewashing Aunt Polly's fence. They supply
the labor, but he gets the reward. On the Internet, users supply the
raw material that helps generate billions of dollars a year in
online advertising revenue. Search requests, individual profiles on
social networks, Web browsing habits, posted pictures and many
Internet messages are all mined to serve up targeted online ads.
Google is a black box. How to work with and not for google.
ABOUT THE GREAT GOOGLE BOOK GRAB
and Google's Monetization of Libraries
GOOGLE 's "Don't be evil" motto was first revealed when the company filed for an IPO in 2004. In 2009 Google has quietly dropped its "Don't be evil" motto as part of a 350 page IPO document detailing its business ambitions. ~ Marissa Mayer, VP of Search Product and User Experience.
Google Apology for being Evil makes explicit an acknowledgment by Google that search engine results can have real impact on real people, and that the referenced Web sites in these results may at times be misleading, defamatory, or otherwise seriously damaging to actual lives.
9/2010 Privacy group sues to get records about NSA-Google relationship The Electronic Privacy Information Center takes NSA to court: says the spy agency should divulge information about its reported agreement to help the Internet company defend itself against foreign cyber attacks. the Google-NSA alliance shows that no single U.S. government agency is responsible for defending the country's private computer infrastructure from the daily onslaught of foreign-based cyber attacks
Government requests directed to Google and YouTube the Requests Tool clarifies how frequently governments ask Google to hand over users' personal data (mostly to assist with law enforcement investigations). The results can be interpreted as an index of governmental willingness to invade privacy. The letter from data protection bureaucrats is clear. Eight of the nine governments that complain so vociferously about Google's privacy policies also appear on this list of governments who take a keen interest in their citizen's private communications. The point is worth arguing. Governments might be keen on regulating Google, but they also represent a huge threat to privacy in their own right. Google itself acts as a restraining influence on their behaviour. This week, the company confirmed that it sometimes “refuses to produce information” or “tries to narrow” the requests for data made by governments.
March 22, 2010 Google Leaves China,closed its Internet search service there and began directing users in that country to its uncensored search engine in Hong Kong . State Council Information Office doesn't like it. Googles search engine based in Hong Kong would provide mainland users results in the simplified Chinese characters used on the mainland and that he believed it was entirely legal. Google said it would retain much of its existing operations in China, including its research and development team and its local sales force. While the China search engine, google.cn, has stopped working, Google will continue to operate online maps and music services in China.
The Lephone does not come with embedded Google search or any pre-installed Google apps, which are common on other Android phones. But a list of Lenovo app partners for the phone included Baidu.com, Google's main rival in the China search market.
March 2010 Google's 'internal intercept' system increased the risk of all Google user data being pirated. If it didn't exist it would be very hard for outsiders to collect it. Wiretapping systems increase security risks and the target is perfect -- wiretap the wiretapper. That's the honeypot. Why buzz around collecting all that data when someone else has done it for you? Why did Google invoking 'human rights' as a pretext for possibly leaving China when it was embarrassed by its internal spying system being compromised by other spies? The hackers , who have not been apprehended, broke through the defences of at least 30 companies, and perhaps as many as 100.The common link in several of the cases that McAfee reviewed is that the hackers used source code management software from privately held Perforce Software Inc, whose customers include Google and many other large corporations. Google's source code had numerous security flaws that would allow easy compromise of a company's intellectual property. Competitive intelligence is commonplace and has a long and very dirty history. All Western allies have been spying on one another for decades, even for centuries
Dec 4, 2009
Google will now personalize the search results of anyone who uses
its search engine
, regardless of whether they've opted-in to a previously existing
personalization feature. Google runs on
a distributed network of thousands of low-cost computers
and can therefore carry out fast parallel processing.
2009 - Now Google LOGS EVERYTHING YOU SEARCH FOR AUTOMATICALY .
2006
With that vast trove of search data,
Google can now PREDICT behavior
. Like with the movie studios. By analyzing search queries,
Google discovered it could predict within a week of a film's
release what the movie's gross would be with approximately
eighty percent accuracy! But the studios said this was not
helpful, because by the time this data snapshot was taken,
they'd already spent their marketing wad, it was TOO LATE! So
Google went back to the numbers. And found out, purely based on
how often people were searching for a film, that SIX WEEKS OUT
they could predict the gross of a movie with EIGHTY TWO
PERCENT ACCURACY!
~Lefsetz
Google KNOWS where you go. NOW your search results are are delivered
to you based on the fact that they know where you go - and will show
you that sites' listings, perhaps when your searches wouldn't have
brought that site up before. Google knows what sites you like and
will show those to you before anything else. Also, just cause you
can't see more than the last 30 minutes of your previous search
history, Google's
is storing much more than that!
- YOU CAN OPT OUT -- By DEFAULT all your searches are logged but you can delete it.
- GET RID OF YOUR SEARCH HISTORY
- Sign into your google accout (yes you have to have one) go to web history and click pause to stop them from recording where you go.
- How to Delete Past History You should know: To include the web pages you visit in your web history, you need to install Toolbar with PageRank enabled. PageRank will send information about these pages to Google and associate it with your Google Account.
-
Personalized Search: Turning off personalization
Personalized Search treats signed-in and signed-out users differently, the instructions for disabling Personalized Search are a little different in each case.
Signed in searches
To disable history-based search customizations while signed in, you'll need to remove Web History from your Google Account. You can also choose to remove individual items. Note that removing this service deletes all your old searches from Web History.
Signed out searches
If you aren't signed in to a Google Account, your search experience will be customized based on past search information linked to a cookie on your browser. To disable history-based customizations, follow these steps:- In the top right corner of the search results page, click Web History .
-
On the resulting page, click
Disable customizations
.(Because this preference is stored in a cookie, it'll affect
anyone else who uses the same browser and computer as you).
Or, if you'd rather just delete the current cookie storing searches from your browser and start fresh, clear your browser's cookies .
Note: If you've disabled search customizations, you'll need to disable it again after clearing your browser cookies; clearing your Google cookie turns on history-based customizations.
- More
Learn how to work with google and use google hacks.
GOOGLE FACTS
-
Google DNS and OpenDNS vs CDNs
- Google Will Own ISP DNS; knows everything you do. Most Internet
providers will outsource their DNS functions to Google.
If Google partners with say Comcast or Time Warner, they can make the change at the server level and it will be done automatically. The ISPs get major cash, Google gets the overwhelming share of the DNS function and users never know anything changed. ( DNS RSS Feed )
Introducing Google Public DNS as part of the ongoing effort to make the web faster , we're launching our own public DNS resolver called Google Public DNS -
Stupid DNS Tricks - Google DNS is way slow, slower than Comcast's default DNS service, and slower than OpenDNS, both of which are quite speedy.
David Ulevitch (Founder of Open DNS) responds to Google DNS - What Google Knows About You and what you can know about Eric from Google.
- Keyhole, the satellite imaging company that Google acquired in October 2004, was funded by the CIA
-
GOOGLE WATCH
Looks at how Google's monopoly, algorithms, and privacy policies are undermining the Web. PageRank: Google's original sin, Google mum on privacy policy. - 2006 Google hired Ori Allon , a doctoral student at the University of New South Wales for his Orion search engine. Google will display your search results with other relevant info in the form of expanded text extracts giving you the relevant information without having to go to the Web site so that search engines can steal web site content without paying for it.
- Matt Cutts, a software engineer at Google since January 2000, used to work for the National Security Agency.
- Google hired Dan Senor as a vice president, who was the chief spokesman in U.S.-occupied Iraq.
- GOOGLE means the number 1 with a 100 zero's after it. "Googol" was coined in 1938 by Milton Sirotta, age 9.
- GOGGLES, eyes. See ogles. Goggle eyes, large prominent eyes; to goggle, to flare. ~ A Classical Dictionary of the Vulgar Tongue by Francis Grose 1785
Excerpt:
"Google's corporate philosophy is based on the model which brought
them success: organizing and giving away other people's content,
creating space for advertisements in the process. The enormous
success Google found with that model in the search engine business
List of Google Search Engines
spurred it to try and impose it in every arena. In the Google
worldview, content is individually valueless. No one page is more
important than the next; the value lies in the page view.
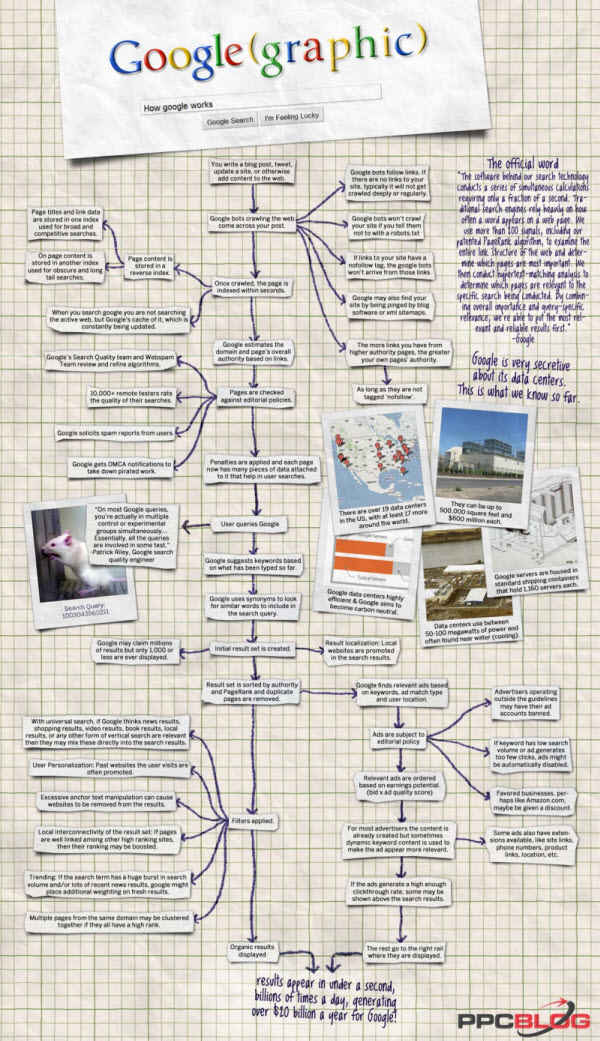
Infographic by PPC Blog Click for Larger Picture
2007
Jimmy Wales Open-source Wikia search engine
gangs up on Google
Wikipedia's co-founder Jimmy Wales attempts to overturn Google's
domination of the search market. Their weapon? The transparency
provided by open source software. The idea underpinning their search
engine - is that its search algorithm, which determines which web
pages appear top of the lists of links it serves up, will be made
public. Wikia's search engineers think this will elicit the trust of
users in a way that Google, which keeps its algorithm a closely
guarded secret, never will. Open source search results will also be
more relevant, as the algorithm will continually be tweaked by its
users, keeping it up to date with new technologies as they are
deployed, Wales says.
The Vanishing Click-Fraud Case
Why was a seemingly slam-dunk case against an alleged click-fraudster who attempted to extort Google quietly dismissed? Google won't discuss specifically how it detects bad clicks or what percent it deems fraudulent, only that it's "less than 10%," saying such information could be helpful to would-be scam artists. Google and its competitors also make money on fraudulent clicks. Here's how it works: Hundreds of thousands of advertisers that market on Google's search engine also let Google distribute their ads to other Web sites. When an ad is clicked on a partner site, both Google and the Web site operator split the revenue and the advertiser is charged. If such a click is bogus, and gets through the search company's filters, Google still profits, at least in the short run.
Clarance Briggs AIT Corporation speaks
http://media.webmasterradio.fm/episodes/audio/2006/googlestory/googlestory1.mp3
WebmasterRadio.FM investigative journalist Jim Hedger:
AIT - x military found google in the al caida blog asked where is
the money going? - is how this got started with the FBI google helps
pro terror fund themselves. WebmasterRadio.FM series on the
implications of click fraud on the industry and on national and
global security. WebmasterRadio.FM is initiating an industry wide
initiative to further examine and confirm issues raised by this
series. The series starts with an interview with Clarence Briggs,
CEO of hosting firm AIT.com. Mr. Briggs was a lead proponent in one
of the class action lawsuits Google settled in the spring of 2006.
Because the case was settled out of court, Google was never forced
to show how they charge for some clicks and dismiss others as
invalid. Mr. Briggs maintains Google is doing business as usual,
just as they did before the class actions were initiated.
During the interview, Mr. Briggs noted the use of click fraud by
criminal and terrorist organizations. Our investigation has found
several incidents of this type of activity. We have also found
evidence of bot-nets used to facilitate click fraud, primarily
against Google advertisers. This series has been in research and
production for over three months. In that time, Jim Hedger and a
number of well-known search marketing experts and analysts have
studied log files supplied by AIT. Each of the search marketing
experts and analysts worked in exclusion of each other, without a
lot of background information, in order to ensure non-biased
examination of the data.
9/13/05 Princeton University's president, Shirley Tilghman, joined Google Inc.'s board of directors this month she also joined the company's seemingly endless parade of wealth. Instead of cash, the online search engine leader is paying Tilghman as it does all its other directors -- with a bushel of prized stock that eventually could turn her Google duties into a better-paying gig than her job running an Ivy League school. ... Tilghman, a molecular biologist, received a $485,000 salary during Princeton's 2002-03 school year, according to the most recent available information from Guidestar.org , which tracks tax returns filed by nonprofits such as the university. The median compensation package for directors at companies in the Standard & Poor's 500 was $139,060 during the fiscal year ending in May 2005, according to Equilar Inc ., a San Mateo, Calif., firm specializing in compensation issues. ...If Tilghman gets lucky, she may get as rich as another Google director from academia, Stanford University President John Hennessey. When Google appointed Hennessey to the board 18 months ago, he received 65,000 stock options now worth about $18 million. Tilghman is the first woman on Google's board, joining Hennessey and eight other wealthy men whose duties include attending most board meetings -- 15 last year.
IPO filed week of 4/26/04
$27 billion - a figure based on the six-year-old company's market
valuation after its first day of trading. 95 percent of all Web
searches in the United States are handled by two companies,
Google
and Yahoo, either directly or through other sites that use their
technology. In the case of
Google
, whose shares started to trade publicly last week, the company
holds the world's largest index of Web content, at more than four
billion pages, and handles more than 200 million searches a day.
Since 2000
,
Google
has recorded your search terms, the date-time of each search, the
globally-unique ID in your cookie (it expires in 2038), and your IP
address. This information is available to governments on request. If
your favorite site features a
Google
search box, ask them to install their own local site search. They
could also use our site search for webmasters, which shows the same
results without the tracking.
http://www.scroogle.org/masters.html
Since March 2007 Google
announces it will start anonymizing their server logs after 18-24
months.
Anonymizing Google's Cookie
:
Why and how to anonymize your
Google
cookie
TIPS: How to Work With Google
Google Inconsistencies : Google does not always behave as advertised nor deliver the results expected. This page aims to document both ongoing and short-lived inconsistent search behavior on Google.
Danny
https://searchenginewatch.com/searchday/article.php/3437471
Gary
http://www.resourceshelf.com/2004/11/wow-its-google-scholar.html
- 11/ 2004 Google now searches over 8 billion pages
- 2003 they administer more than 100,000 servers.
- 2002 Google index now searches 2,469,940,685 pages that is almost 2.5 billion pages which is still only searching a fraction of the Web!! Google is now indexing flash pages and reading the text in it, alltheweb.com also does.
TOOLS
- SEARCH FOR FREE by David Dillard All you need is a public library card which gives you online access to the very expensive databases where you can get everything for free.
- Pro's and Con's of working with Internt Search engins vs. Databases found at public or university Libraries.
- BioMed Central has developed a Google Scholar search plugin for FIREFOX
- 2006 Download Google Cheat Sheet
- Google Book Search Beta
- Google special search engine for BSD + Macintosh
- Google's Book Search offers snippets that help you write right that term paper .
- Google Print (TM) Service, of which this deal is to be a part, provides links to booksellers as well as to libraries. Though they have not announced plans to offer the full text of copyrighted materials on a pay-per-view basis, with fees turned over to copyright owners, it is a technical possibility with the natural force of an economic vacuum in the corporate context.
- Google Scholar allow users "to search specifically for scholarly literature, including peer-reviewed papers, theses, books, preprints, abstracts and technical reports from all broad areas of research." This includes results from the Open WorldCat program , which is particularly important since much of this material isn't available in electronic format yet. It will be even more useful after Google has harvested all 57 million WorldCat records, instead of the 2 million records in the pilot subset. It's a single search tool, and no single search tool searches the entire bibliographic universe. It does not offer full disclosure about content (what is and is not included) in the database. Current research appears late in the database. Indexing is incomplete. It does not provide equal coverage of all subject areas
-
"Google in Your Language" Check
your preferences
A machine translation of search results, which will only give you the main idea of what you are reading. All your search results in Spanish, German, French, and Portuguese will have a "translate this page" link beside them. Click on it and you'll get a translated page framed by Google. If you have "Search only these selected languages" checked, and none of the languages are the ones named in the last paragraph, you won't see the "translate this page" link. You can now specify that you want titles and page summaries in Spanish, German, French and Portuguese translated directly on the results page but it doesn't always work. - GOOGLE just for the US GOV
- Google Earth https://earth.google.com/
- Googlematic
- Google Smackdown
-
Remove a site from Google
With a vast system of more than 10,000 computer systems constantly collecting new information on more than 3 billion Web sites, the company cannot and does not want to police or censor what goes on the Web, said Craig Silverstein, Google's chief technology officer. "I think Web masters have to be careful," he said. "The basic problem is that with 3 billion [Web sites], there's a lot of information out there." It offers a tool on its own Web site, "Webmaster guidelines," on how to remove Web sites from Google's system, including Google's vast store of cached pages that may no longer be available online, Silverstein said. - Year End Google Zeigeist
- Googlewhacks
Google Hacks
For hacking experts, Google-hacking has a kind of populist allure:
any one with Internet access can do it if they know the right way to
search.
Search strings including "xls," or "cc," or "ssn" often brings
up spread sheets, credit card numbers, and Social Security
numbers linked to a customer list. Adding the word "total" in
searches often pulls up financial spreadsheets totaling dollar
figures. A hacker with enough time and experience recognizing
sensitive content can find an alarming amount of supposedly
private information.
The availability of private information contributes to rising
incidence of
Identity Theft, which for the last four years has been the No. 1
consumer problem for the Federal Trade Commission
.
Last year the FTC received nearly 215,000 complaints about
identity theft, up from about 152,000 in 2002.
Since 2001, the FTC has settled cases with Eli Lilly & Co.,
Microsoft Corp. and clothing maker Guess Inc. for not taking
"reasonable" measures to keep medical or financial information
secure, said Jessica Rich, assistant director of the commission's
bureau of consumer protection. Letting customer information reside
on an unsecure server can open up a business to such liability.
"There are unique vulnerabilities because of databases that are
accessible through the Web," Rich said, adding that the FTC
anticipates bringing more security-related cases in the future.
GOOGLE PRIVACY
User Tracking
OrgName: Google Inc.
OrgID: GOGL
Address: 1600 Amphitheatre Parkway
City: Mountain View StateProv: CA PostalCode: 94043 Country: US
NetRange:
66.249.64.0
-
66.249.95.255
CIDR: 66.249.64.0/19 NetName: GOOGLE
NetHandle: NET-66-249-64-0-1
NetType: Direct Allocation
NameServer: NS1.GOOGLE.COM
NameServer: NS2.GOOGLE.COM
Comment: RegDate: 2004-03-05 Updated: 2004-11-10 OrgTechHandle:
ZG39-ARIN OrgTechName: Google Inc. OrgTechPhone: +1-650-318-0200
OrgTechEmail: arin-contact@google.com
Govt claims warrantless access to e-mail via third party servers
and
Google GMAIL POLICY
Google doesn't delete your gmail emails when you trash them, but
continues to keep them on their servers in storage.
[... The subpoena asks for not only current e-mail but also deleted e-mail: "All documents concerning all Gmail accounts of Baker...for the period from Jan. 1, 2003, to present, including but not limited to all e-mails and messages stored in all mailboxes, folders, in-boxes, sent items and deleted items, and all links to related Web pages contained in such e-mail messages." Google's privacy policy says deleted e-mail messages "may remain in our offline backup systems" in perpetuity. It does not guarantee that backups are ever deleted. Baker estimated he may have tens of thousands of e-mail messages in his Gmail account.In a Jan. 31 ruling, Laporte rejected Baker's request. She said his attorney could withhold "truly protected" information but must "err on the side" of disclosure. ] Police Blotter
Email privacy is an enormous issue.
The
EFF
informs us that companies which offer both internet search and email
storage can collect a massive amount of personal information about
users. It's possible to extract information about you from the
searches you make. It's also possible for an email host to scan your
emails to collect other personal details about you. Not only
possible, but the big players like Yahoo, MSN and Amazon do this.
Google Watch
reports that Google scans all of its clients' emails and reserves
the right to "give this information to whomever they wish. . . After
180 days in the U.S., email messages lose their status as a
protected communication under the Electronic Communications Privacy
Act.
EPIC explains Google's email privacy policy
Google has a great image as a good company. They have engendered a
great amount of trust through their "Don't Be Evil" motto. They are
getting dangerous. The fact is that
they are stockpiling a perilous amount of personal information
about their users. Google logs every search request with its IP
address.
Google has acknowledged this log in a number of interviews. But,
they have never answered why they keep such a log. The search log by
itself is not too harmful since the IP address identifies a computer
and not a person. The searches cannot easily be traced to a
particular person without help from the ISP.
THEY KEEP THE INFORMATION FOREVER!
"A bigger problem is that many Google search users are also Gmail
users, and a cookie is shared between Gmail and Google search
(because they use the same domain, google.com). Therefore, if a
person uses Gmail and Google search from the same computer, even
with a long period of time in between, Google will know the identity
of the person responsible for those search queries.
Google doesn't need to infer your identity from the content of
your other web searches; it already knows it, if you're a Gmail
user.
This identification can be retroactive. If you used Google search
for 3 years on a particular PC, and then signed up for a Gmail
account, your search cookie from that PC would be sent to Google and
the name you provided for your Gmail account could then be
associated retroactively with your entire saved search history.
Google cookies last as long as possible -- until 2038.
If you've ever done a Google search on a given computer with a given
web browser, you probably still have a descendant of the original
PREF cookie that Google gave you upon your very first search, with
the very same ID field (a globally unique 256-bit value).
This problem is ubiquitous in the web portal industry, and Google is
right to say that its privacy policy is better than many of its
competitors'. However, Google is still assembling a treasure trove
of personal information, possibly stretching back for years, that
Google may release in response to any civil subpoena or
"governmental request":
https://gmail.google.com/gmail/help/privacy.html#disclose
"
Seth David Schoen
http://www.loyalty.org/~schoen/
--
Question: Does Google retain logs of personally identifiable search data?
My full blog Answer posting
When Google launched "My Search History" in April 2005, Google's VP
of Engineering, Alan Eustace told
InternetWeek:
With 'My Search,' however, information stored internally with Google
is no different than the search data gathered through its Google.com
search engine, Eustace said. "This product itself does not have a
significant impact on the information that is available to
legitimate law enforcement agencies doing their job."
As I asked in a blog posting at that time: Is he really saying that
Google already captures and stores search data tied to unique users?
Unfortunately, Google's privacy policy is pretty vague on the issue.
... Eustace may have misspoken... but really he didn't.
According to the "My Search History (Beta) - Privacy FAQ," you may
feel free to edit the logs, but Google is still keeping copies of
the unedited searches
.
So there you have it: a comprehensive log of your searches tied to
your identity, available to law enforcement bearing warrants and
litigious people bearing civil subpoenas.
Signing up for the service simply provides them an easier way to
wrap the data into a tidy duces tecum package! So, in other words,
you are already using My Search History, and you didn't even know
it!
- Google is not just a company. If any company wants to be found by customers, wants to make sales on the web, or wants to be part of the modern world, it has to be findable in Google. People under 35 don't use telephone books, magazines, or newspapers anymore. They use Google. It's not a choice "to not be on Google". Google isn't a company: it has become the infrastructure for the delivery of information.
-
Lauren Weinstein writes about the privacy issues at Google. It's
far more serious than privacy. Very few people understand how
Google works. There isn't "one Google" and the results you see in
your search in Miami are not the same as the results someone else
sees in Seattle. - Google constantly adjusts the results according
to many parameters, incl. user personalization (Google Toolbar),
the length of the user's search session (you may get different
results during your session), your physical location, and so on.
- There are millions of searches and results, and these constantly shift. This means it is literally impossible for anyone outside of Google to track the search results.
Results don't appear consistently. They can appear intermittantly. Instead of appearing 100% of the time, a result can appear for 90% of searches or 80% of searches. There is no way to track this.
- It would be easy for Google to slightly suppress a result. So a search for a particular company would only appear for 97% of searches. That's a small amount, but it is significant for ecommerce. This means Google can manipulate the sales and valuation of companies.
- It works the other way too. Google can "over-produce" results for a publically-traded company. Their earnings and valuation rise slightly. -
Google's ability to suppress (or enhance) results isn't theory.
Google has a secret team that suppresses the ranking of people
who criticize Google. Never complain about Google in Gmail, in a
public forum, or wherever your comments will be found by Google.
Your rankings will slide down just a bit. You will lose web
traffic to your website, your blog, or your company.
This means that Google doesn't have to blacklist you. Nothing that blatant. They just lower your ranking. End of problem. Nobody can prove anything, because Google is an informational black hole; they never reply. -
The privacy issues are thus both ways: the right to keep one's
information private, and the right to publicize one's information.
It's bad to lose privacy, but what is it when one's public persona
is downranked by Google and one can't be found in searches?
Professors, researchers, journalists, etc. can be removed from
public access. And remember: Google doesn't have to blacklist you.
They only have to lower your ranking. Or show you in the results
only intermittantly.
Microsoft was (and still is) a monopoly. But you can use your copy of Microsoft Word to write whatever you like. - Google is a far greater danger than Microsoft. Write your emails in GMail, use Google word processor, the Google spreadsheet, Google video, or any of the endless Google tools, and they correlate everything about you. Google can read all of your emails, docs, and spreadsheets. By merely suppressing or enhancing results, they can make vast profits, erase careers, and literally control economies. This creates spectacular power. No company has ever been able to resist that kind of temptation.
Matt Cutts and Danny Sullivan on SEO/SEM Black Hats
Matt Cutts or Danny Sullivan provide SEO, & SEM Black Hat Organic Results.
SEO Held Liable, Fined In Counterfeiting Case
Jury Awards Damages Against Web Designer/SEO/Host on
Contributory Trademark Infringement Theory
--Roger Cleveland v. Prince By Eric Goldman
Roger Cleveland Golf Co. v. Prince, 2:09-cv-02119-MBS (D.S.C. jury
verdict March 10, 2011 and judgment March 14, 2011). See also the
jury instructions.
web design/SEO/host firm working with online retailer of
counterfeit goods could be liable for contributory trademark
infringement. The ruling didn't make any sense substantively, but
the court clearly didn't appreciate the defense counsel's 1.5 page
citationless summary judgment brief. The court separately ruled
that the website did engage in counterfeiting--thus removing that
issue from the jury's consideration--leaving two principal
questions for the jury: (1) was the designer/SEO/host secondarily
liable, and (2) damages.
In the Sunday edition of the New York Times' business section 2/19/2011 was an investigatory piece on JCPenney's SEO campaign by David Segal. The article, entitled “The Dirty Little Secrets of Search,”
JCPenney was beating everyone, ranking in the top position for every term. What the article uncovers is that JCPenney's organic campaign is built on a landscape of 2,015 links to unrelated websites. Terms like “evening dresses,” “casual dresses,” and “cocktail dresses” are linked to online gambling, banking and, most comically, U.S. clergymen sites.
The linking scheme of this scale went un-reacted upon by Google for so long then once in the NYT they sent Matt Cutts, who runs Google's Webspam team, to address the JCPenney situation with the NYTimes by finally demoting their organic listings.
Claire Cain Miller wrote in the technology section of the New York Times , which probes at AOL's recent acquisition of the news site Huffington Post, asking if it isn't a ploy to drive traffic with low quality journalism. Miller argues that HuffPo leverages SEO tactics to boost its worth to increase readership and display ad revenue. Or what about the “Google: Bing is copying our results” scandal at the beginning of the month? Who outside of search marketers had ever heard of Danny Sullivan before his scandalous article blew up across the blogosphere and even made it into The Colbert Report ?
Google Trust Rank assessed by humans!!
Microsoft has announced a significant change to its paid search editorial policy, which will enable marketers to bid on trademark terms across Bing and Yahoo!. The new policy permits marketers to bid on their competitors' brand terms, however they are still not allowed to include trademark terms in their ad copy. The change will come into effect on March 3, 2011.
SEO and SEM Black Hat Organic Results
SEO, & SEM Black Hat Organic Results.
Urchin Software Corp. The unlikely origin story of Google Analytics, 1996-2005-ish and the comments
SEO Held Liable, Fined In Counterfeiting Case
Jury Awards Damages Against Web Designer/SEO/Host on
Contributory Trademark Infringement Theory
--Roger Cleveland v. Prince By Eric Goldman
Roger Cleveland Golf Co. v. Prince, 2:09-cv-02119-MBS (D.S.C. jury
verdict March 10, 2011 and judgment March 14, 2011). See also the
jury instructions.
web design/SEO/host firm working with online retailer of
counterfeit goods could be liable for contributory trademark
infringement. The ruling didn't make any sense substantively, but
the court clearly didn't appreciate the defense counsel's 1.5 page
citationless summary judgment brief. The court separately ruled
that the website did engage in counterfeiting--thus removing that
issue from the jury's consideration--leaving two principal
questions for the jury: (1) was the designer/SEO/host secondarily
liable, and (2) damages.
In the Sunday edition of the New York Times' business section 2/19/2011 was an investigatory piece on JCPenney's SEO campaign by David Segal. The article, entitled “The Dirty Little Secrets of Search,”
JCPenney was beating everyone, ranking in the top position for every term. What the article uncovers is that JCPenney's organic campaign is built on a landscape of 2,015 links to unrelated websites. Terms like “evening dresses,” “casual dresses,” and “cocktail dresses” are linked to online gambling, banking and, most comically, U.S. clergymen sites.
The linking scheme of this scale went un-reacted upon by Google for so long then once in the NYT they sent Matt Cutts, who runs Google's Webspam team, to address the JCPenney situation with the NYTimes by finally demoting their organic listings.
Claire Cain Miller wrote in the technology section of the New York Times , which probes at AOL's recent acquisition of the news site Huffington Post, asking if it isn't a ploy to drive traffic with low quality journalism. Miller argues that HuffPo leverages SEO tactics to boost its worth to increase readership and display ad revenue. Or what about the “Google: Bing is copying our results” scandal at the beginning of the month? Who outside of search marketers had ever heard of Danny Sullivan before his scandalous article blew up across the blogosphere and even made it into The Colbert Report ?
Microsoft has announced a significant change to its paid search editorial policy, which will enable marketers to bid on trademark terms across Bing and Yahoo!. The new policy permits marketers to bid on their competitors' brand terms, however they are still not allowed to include trademark terms in their ad copy. The change will come into effect on March 3, 2011.